深度学习笔记-卷积神经网络构建

想做图像识别,刚接触AI相关的东西,搞了好多天才弄懂一些基础概念,比如机器学习,深度学习的区别等等。 图像识别要怎么做,主要通过卷积神经网络(RNN)来做,卷积又是啥呢,网络又是啥,这些基本通过一天学习就能搞清楚,前提是有个好个教程,推荐 AI By Doning
然后跟着例子把卷积神经网络实现一遍,主要是里面的一些代码细节需要扣一下,否则会陷入感觉懂了,实际啥也写不出来的尴尬陷阱
1. 机器学习&深度学习&神经网络
机器学习是实现人工智能的一种方式,深度学习属于机器学习范畴,人工神经网络又属于深度学习的,人工神经网络有包含卷积神经网络和循环神经网络等;
卷积神经网络常用于图像分类识别等场景,循环神经网络常用于NLP自然语言处理
2. 卷积神经网络简介
卷积神经网络主要用于图像识别,卷积的作用是用于提取图像特征,有一个叫卷积核的东西,通过设置不同的卷积核参数,可以对图像逐行扫描或者多行扫描,完成图像特征提取,然后通过神经网络去进行分类。
对卷积的介绍不是本文重点,可以参考这里
3. 卷积神经网络构成
一般卷积神经网络构成包含:
- 卷积层 - 通过卷积核完成对图像的卷积;
- 池化层 - 对图像进行采样缩放,包括平均池化和最大池化
- 全连接层 - 对图像进行分类预测等
4. 经典的卷积神经网络
包括:
LeNet - LeNet-5 是一个很早的经典卷积神经网络。Yann LeCun 在1998年创建,用于识别美国支票上手写数字。
AlexNet - 2012年ImageNet大赛上大放异彩,相比第二名图像识别率提高 10%,作者之一就包含OpenAI -ChatGPT 大模型科学家 Ilya Sutskever (现已离职)。
大家有兴趣可以搜索下这几个Net的法明人的关系,或师徒或朋友或同事,现在好多都在大公司深处要职,研究最前沿的AI技术。
还有其他很多… 如 VGG, Google Net, ResNet等,这些网络都是通过设置不同的卷积层和池化层,进行排列组合优化之后的结果,根本原理还是相同的。
5. 卷积神经网络搭建
到了本文重点,以 LeNet-5卷积神经网络为例,结构比较简单,了解了它就对卷积神经网络有了直观认识,也算入门了。前提是代码吃透,细节吃透,然后以这个为基础拓展不了解的东西,慢慢对整个神经网络进行熟悉和应用。
详细流程可以参考这里,本文主要是对一些关键代码的解析
5.1. LeNet网络结构
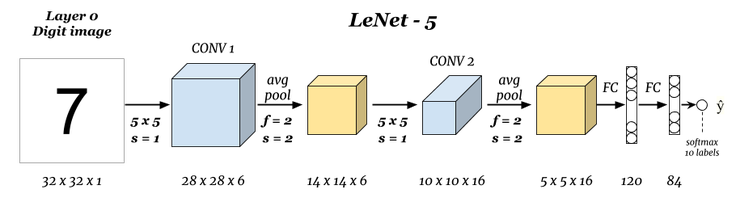
5.2. 数据读取和预处理
主要是使用python读取原始数据,熟悉代码,加深python的使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import gzip
import numpy as np
def read_mnist(images_path, labels_path):
with gzip.open("MNIST_data/" + labels_path, "rb") as labelsFile:
y = np.frombuffer(labelsFile.read(), dtype=np.uint8, offset=8)
with gzip.open("MNIST_data/" + images_path, "rb") as imagesFile:
X = (
np.frombuffer(imagesFile.read(), dtype=np.uint8, offset=16)
.reshape(len(y), 784)
.reshape(len(y), 28, 28, 1)
)
return X, y
train = {}
test = {}
train["X"], train["y"] = read_mnist(
"train-images-idx3-ubyte.gz", "train-labels-idx1-ubyte.gz"
)
test["X"], test["y"] = read_mnist(
"t10k-images-idx3-ubyte.gz", "t10k-labels-idx1-ubyte.gz"
)
train["X"].shape, train["y"].shape, test["X"].shape, test["y"].shape
输出未 4维的张量,关于张量可以认为是多维数组,参考
1
((60000, 28, 28, 1), (60000,), (10000, 28, 28, 1), (10000,))
关键代码解释:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# gzip.open 是 Python 中用于处理 gzip 压缩文件的函数:
# 打开 gzip 压缩的文件,支持读写操作。
# 读取时,自动解压缩内容;写入时,自动进行 gzip 压缩。
# 参数与 open 类似,增加 mode 指定操作模式(如 "rb" 表示二进制读)。
# 通常用于处理压缩的日志文件或数据存档。
# # --------------------------------------------------------------------
# with 语句在 Python 中用于处理资源的上下文管理,确保资源被正确地获取和释放:
# 简化资源管理:自动处理资源的获取和释放。
# 提高代码可读性:使代码更加清晰和简洁。
# 保证资源释放:即使发生异常,也能确保资源被正确关闭或释放。
# with 语句常用于文件操作、数据库连接、网络连接等场景。使用 as 关键字可以给资源创建一个临时变量,方便在代码块中使用。例如:
# with open('file.txt', 'r') as file:
# content = file.read()
# 在这个例子中,file 变量在 with 代码块内表示打开的文件对象,当执行完代码块后,文件会自动关闭。
# # --------------------------------------------------------------------
# labelsFile.read() 读取的是标签文件的全部内容,返回的是一个字节串(bytes 类型)。具体来说:
# 读取内容:read() 方法读取整个文件的内容,并返回一个字节串。
# 字节串:这个字节串包含了文件中的所有字节数据。
# 在你的代码中,np.frombuffer() 将这个字节串转换为 NumPy 数组,其中:
# dtype=np.uint8 指定每个元素为无符号 8 位整数。
# offset=8 表示跳过前 8 个字节(通常是文件头信息)。
# 因此,labelsFile.read() 读取的是标签文件的全部字节数据,后续通过 np.frombuffer 解析为标签数组。
# # --------------------------------------------------------------------
# reshape的作用:
# reshape 是 NumPy 中用于改变数组形状的方法,其作用如下:
# 改变形状:将数组重新塑形为指定的新形状,而不改变数组的数据。
# 参数说明:
# 第一个参数 len(y):指定新数组的第一个维度大小,即样本数量。
# 第二个参数 784:指定新数组的第二个维度大小,即将每个样本展平为 784 个像素。
# 具体来说,在这段代码中:
# X 是一个一维数组,包含所有图像数据。
# reshape(len(y), 784) 将 X 转换为二维数组,形状为 (样本数量, 784)。
# 这一步是为了将原始的一维数组转换为每个样本对应 784 个像素的形式,便于后续处理。
# # --------------------------------------------------------------------
# train["X"] 这种语法是 Python 字典(dictionary)的一种访问方式。
# 解释
# train:这是一个字典(dictionary)变量。
# "X":这是字典中的一个键(key)。
# 通过这种语法,可以访问字典中与键 "X" 对应的值(value)。
可视化其中一个元素图像
1
2
3
4
5
6
7
8
9
10
11
from matplotlib import pyplot as plt
%matplotlib inline
plt.imshow(train["X"][0].reshape(28, 28), cmap=plt.cm.gray_r)
# ---------------
# 设置Jupyter Notebook内联显示图形。
# 从训练数据train中获取第一个样本的图像数据。
# 将一维数组重塑为28x28像素的二维图像。
# 使用灰度色彩映射显示图像。
样本 padding 填充 主要是为 卷积核做卷积准备,防止图像宽度不能正好被卷积核整数次卷积做准备
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 样本 padding 填充
X_train = np.pad(train["X"], ((0, 0), (2, 2), (2, 2), (0, 0)), "constant")
X_test = np.pad(test["X"], ((0, 0), (2, 2), (2, 2), (0, 0)), "constant")
# 标签独热编码
y_train = np.eye(10)[train["y"].reshape(-1)]
y_test = np.eye(10)[test["y"].reshape(-1)]
X_train.shape, X_test.shape, y_train.shape, y_test.shape
# -------解释-----------
# np.pad 是 NumPy 库中的一个方法,用于对数组的边缘进行填充。具体解释如下:
# 参数:
# array:要填充的数组。
# pad_width:一个元组或可迭代对象,指定每个轴上的填充宽度。格式为 ((before_1, after_1), ... (before_N, after_N)),其中 N 是数组的维度数。
# mode:填充模式,如 "constant" 表示用常数值填充。
# 其他参数根据不同的模式而变化。
# 作用:
# 按照指定的方式,在数组的边缘添加额外的数据,从而改变数组的大小。
# 例如,np.pad(array, ((1, 2), (2, 1)), "constant") 表示在二维数组的第一维前面加1列、后面加2列,在第二维前面加2行、后面加1行,并用常数值填充这些新增的部分
# # -----------
# np.eye 是 NumPy 库中的一个函数,用于创建一个单位矩阵(identity matrix)。具体解释如下:
# 参数:
# N:生成的单位矩阵的大小(通常是行数和列数)。
# 可选参数 k:对角线的位置,默认为 0(主对角线)。
# 返回值:
# 一个 N×N 的单位矩阵,其中主对角线元素为 1,其余元素为 0。
独热编码
其实就是一个映射,比如有个数组3个元素:学生,老师,工人,可以把他们映射成 学生 -> 0,老师 -> 1, 工人 -> 2,也就是把字符串使用 数字表示,便于计算机处理和匹配。
这只是一个简单直观的认识,当然没有这么简单,参考
5.3. 使用TensoFlow构建网络
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import tensorflow as tf
model = tf.keras.Sequential() # 构建顺序模型
# 卷积层,6 个 5x5 卷积核,步长为 1,relu 激活,第一层需指定 input_shape
model.add(
tf.keras.layers.Conv2D(
filters=6,
kernel_size=(5, 5),
strides=(1, 1),
activation="relu",
input_shape=(32, 32, 1),
)
)
# 平均池化,池化窗口默认为 2
model.add(tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=2))
# 卷积层,16 个 5x5 卷积核,步为 1,relu 激活
model.add(
tf.keras.layers.Conv2D(
filters=16, kernel_size=(5, 5), strides=(1, 1), activation="relu"
)
)
# 平均池化,池化窗口默认为 2
model.add(tf.keras.layers.AveragePooling2D(pool_size=(2, 2), strides=2))
# 需展平后才能与全连接层相连
model.add(tf.keras.layers.Flatten())
# 全连接层,输出为 120,relu 激活
model.add(tf.keras.layers.Dense(units=120, activation="relu"))
# 全连接层,输出为 84,relu 激活
model.add(tf.keras.layers.Dense(units=84, activation="relu"))
# 全连接层,输出为 10,Softmax 激活
model.add(tf.keras.layers.Dense(units=10, activation="softmax"))
# 查看网络结构
model.summary()
代码解析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 该Python代码段使用TensorFlow库构建了一个神经网络模型的一部分:
# 创建一个顺序模型model。
# 向模型添加卷积层:使用6个大小为5x5的卷积核,步长为1,激活函数为ReLU,输入形状为(32, 32, 1)。
# -----
# 为什么要用6个卷积核
# 从LeNet的网络结构图示可以看到,其第一层卷积层使用了6个卷积核
# -----
# tf.keras.layers.Flatten() 的作用是:
# 将输入的多维张量转换为一维向量。
# 用于连接卷积层(或多维输出)和平坦的全连接层(Dense层)。
# 保留所有像素信息,仅改变数据形状,便于后续全连接层处理。
# -----
# tf.keras.layers.Dense 的作用是:
# 实现一个全连接层。
# units=120 表示输出维度为 120。
# activation="relu" 使用 ReLU 激活函数,引入非线性特性,帮助模型学习更复杂的模式。
可以看到使用 TensorFlow提供的高级接口,很容易就实现了 LeNet,关键还是对这个过程的理解,需要自己跑下代码体会一下,跑和不跑代码是两种感觉,两回事。
另外还可以通过 TensorFlow提供的低阶 API构建下 LeNet,或者使用 PyTorch 构建一下,多了解下,慢慢体会
6. 为什么要了解 LeNet
那个了解 LeNet 有什么用呢?构建 Net 主要是训练模型使用的,可以把参数进行调优,其中还包括欠拟合和过拟合等问题,了解网络结构可以从结构上提升精度和模型计算速度等。
7. 代码工具
另外跑代码使用可以多使用类似 通义灵码 类似的 VS Code 插件去解析一些代码细节,如 python的语法等,加深对代码的认识。
另外好多人使用跑python的工具是 jupyter notebook,使用前感觉不就是个web页面跑python嘛,使用后感觉还挺方便,比开个终端或者建个 vscode 文件跑起来舒服一点。相关资料可自行搜索,网上挺多。
8. 结语
跑完 LeNet 你会发现,即使对卷积神经网络的细节原理不了解,也可以做深度学习开发,只要对每一层的作用有个大概了解就可以。
这种感觉就像我不知道显卡,内存,主板的具体工作原理,但不妨碍我把他们组装起来,变成电脑使用,我只要知道每个部件的作用,以及对应的接口就可以了。
模型如何训练呢,训练好的模型如何使用呢,MNN, NCNN这些框架又是做什么的?后面有时间再写写
另外网上资料太繁杂,良莠不齐,我也是找了好久,教程再次推荐: AI By Doning
最后说,一定要多练习,不要眼高手低,纸上得来终觉浅,绝知此事要躬行!
