为什么-WebRTC-移除BBR拥塞控制算法

WebRTC 在 Bug: webrtc:9883 移除了 BBR 拥塞控制算法,给出的原因也比较简单:
关于 BBR 被WebRTC移除国内网上也有一些介绍,大多来源于这两个帖子:
里面提到:
However, BBR was deprecated due to some “performance issues” and removed from the codebase.
但国内的人似乎把 performance 翻译成了 性能,容易让人有误解,以为 BBR 在性能消耗性有问题,其实翻译为表现更准确一些。
BBR的表现
那么 BBR 究竟什么表现让 WebRTC 移除了它呢?
帖子 1的作者给出实测数据:
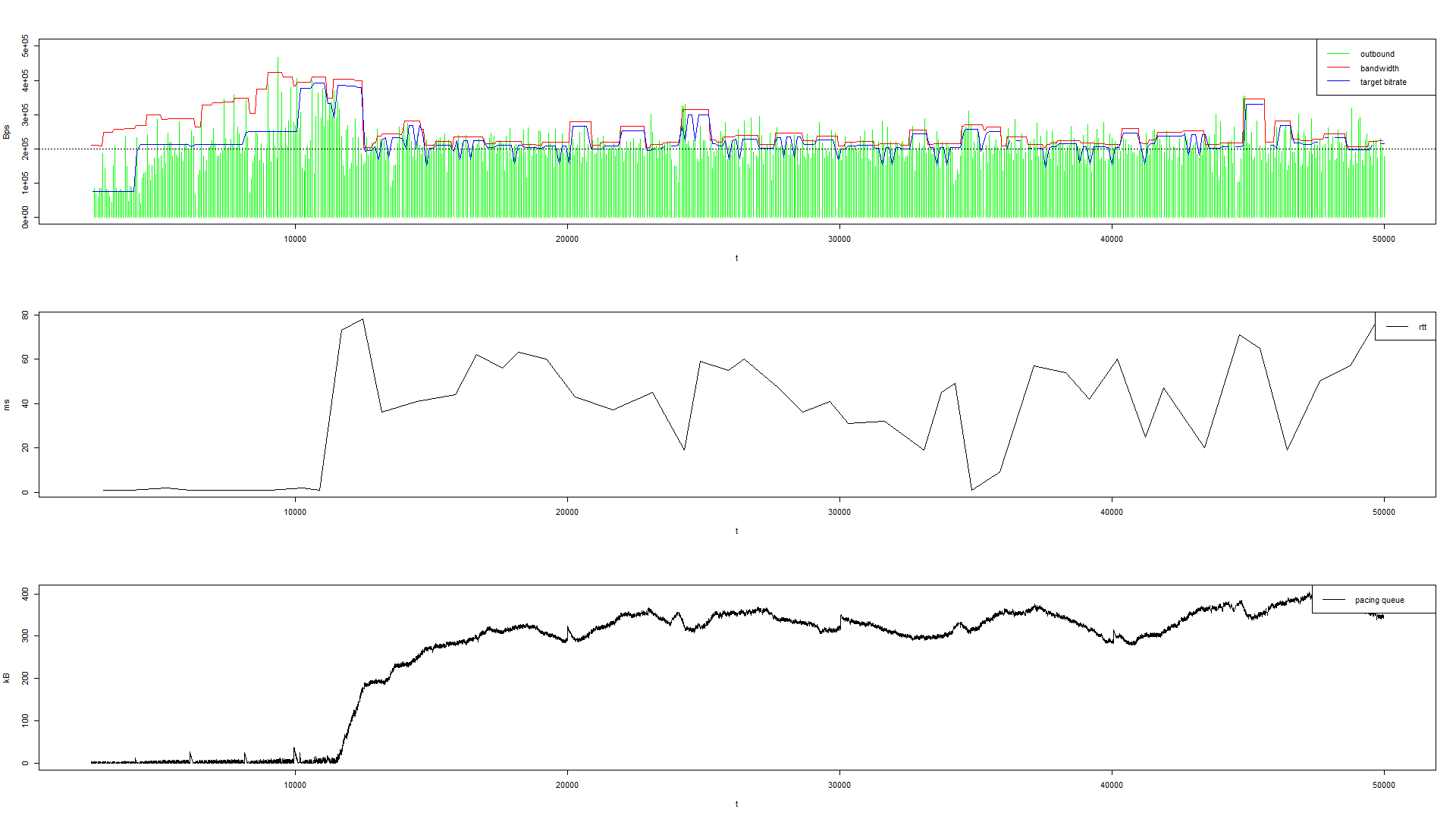
第一张图:红线是由 BBR 给出的带宽测量结果。蓝线是相应的建议编码比特率(由自适应编码模块给出)。绿色类似直方图的线条表示实际的发送带宽。水平虚线是真实的带宽数值。
第二张和第三张图代表了相应的往返时延(RTT)和 pacing 队列大小。它们共同决定了服务器和客户端之间的延迟。
根据实验结果(上图),当 BBR 对带宽进行过高估计时,自适应编码模块会增加编码器的目标比特率。这与大批量传输非常不同,因为过高估计不会增加待发送数据的总量。增加的比特率会导致拥塞。当飞行数据受 CWND 限制时,剩余的数据将积压在 pacing 队列中,导致服务器和客户端之间出现明显的延迟。
也就是说,当 BBR 估测出一个高于实际带宽的值时,作用于编码器,编码处的码率则高于实际带宽,就会造成包在 pacing 中排队, rtt 也相应增大。
如果堆积的包数量超过 pacing 队列的阈值,大量数据包又会发送到网络上,造成拥塞恶化,严重丢包。
why bbr is removed from webrtc 这篇国内文章有探讨这个现象。
对此有谷歌开发者解释:
一个问题是轻微的带宽过估计,就像你观察到的那样。应用最大过滤器会使即使是小的过估计也相当持久。如你的图所示,这个问题在启动阶段(STARTUP)最严重,因为带宽估计受到发送速率的限制,而在启动阶段的发送速率明显高于带宽估计。我们可能在带宽估计器中有一个尚未发现的错误,但在存在ACK聚合的情况下也存在已知的过估计可能性。
在我们的测试中,流程经常处于应用限制状态,这可能会阻止错误的带宽估计从STARTUP中快速过期,但考虑到你的测试中存在一个持续存在的队列,这似乎不是一个因素。
我们观察到的最后一个问题是在WebRTC流的双向使用BBR时,特别是在从STARTUP阶段退出所需的时间较长时,最小往返时间(min_rtt)估计会被夸大。
见:帖子 1
另外一个WebRTC 移除 BBR 原因在帖子 2 有提到:
I don’t think there are any plans for using BBR. One of the problems with BBR for real-time communications is that it alternates between probing the bandwidth and measuring the RTT. To measure the bottleneck bandwidth, we need to build network queues. To accurately measure the RTT, all network queues must be completely drained which requires sending almost nothing for at least one RTT. These variations in target send rate do not play nice with encoders and jitter buffers.
我认为目前没有使用 BBR 的计划。BBR 在实时通信中的一个问题是它在探测带宽和测量往返时延(RTT)之间交替。要测量瓶颈带宽,我们需要建立网络队列。要准确测量 RTT,所有网络队列都必须完全排空,这要求至少在一个 RTT 内几乎不发送任何数据。这种目标发送速率的变化对编码器和抖动缓冲器来说并不友好。
也就是说 BBR 和 WebRTC 的编码器以及Jitter Buffer 配合不好
思考
从现有资料看(@PixPark 没有实测),BBR 在带宽估计上要比 GCC 准确,在收敛性上也比 GCC 迅速,这是 BBR 的优点。WebRTC 自从引入 BBR 依赖,网络上关于它的讨论很多,国内好多RTC 开发者对BBR 寄予厚望。
既然 BBR 属于实验性的功能,实际和 WebRTC 配合表现又不是太好,那是不是 BBR 就不能在 RTC 中应用了?
个人认为如果是对带宽准确性要求较高的场景,比如说在服务端对 SVC 编码层转发丢弃的场景,可以利用 BBR 带宽准确的特点,比较准确的对下行进行转发数据包。
另外就是根据自己的要求对 BBR 进行调参,调优,比如按照探测带宽的 80% 给编码器设置码率(可能是个馊主意)。
还有一点疑问是在带宽变动比较大的场景,如楼道走动等,BBR 的适应性怎么样?需要进一步探索
本文对 BBR 的讨论并不深入,并且带了一些疑问,主要是让大家对 WebRTC 移除BBR 有个了解。对这块比较了解的朋友,希望分享你的观点和看法。
参考
整理了一些关于 BBR 和网络相关的参考文章:
why bbr is removed from webrtc
结果令人失望的 bbr2
真实网络中的 bbr
揭露 bbr 的真相
长肥管道:为何文件传输速度这么慢
网络协议–TCP的未来和性能
